Выбор читателей




Популярные статьи
Цена которого составляет всего $229,99. Это первый в мире смартфон который будет оснащен технологией распознавания глаза 2-го поколения.
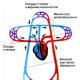
Однако, когда речь идет о распознавании радужки глаза, люди склонны путать его с другим видом технологии идентификации под названием “сканирование сетчатки”. Сегодня в этой статье мы хотели бы обсудить сходства и различия в деталях между видами сканирования глаз.
Как определяются две технологии идентификации на основе глаз?
Распознавание радужки глаза
Распознавание радужки глаза, как биологическая система аутентификации, представляет собой автоматизированный метод, который использует математические методы распознавания образов на видеоизображении одного или обоих зрачков глаз индивидуума, чей комплекс случайных моделей являются уникальными, стабильными, и их можно увидеть с некоторого расстояния.
Сканирование сетчатки
Сканирование сетчатки – это совсем другое, основана но глазной биометрической технологии, которая использует уникальные узоры на сетчатке глаза кровеносных сосудов человека. Человеческая сетчатка представляет собой тонкую ткань которая состоит из нервных клеток, расположенных в задней части глаза.
Сходства между распознаванием радужки и сканированием сетчатки глаза.
В биометрии, радужная оболочка и сканирование сетчатки глаза являются “глазной основой” технологии идентификации, которые основаны на уникальных физиологических характеристиках глаза для идентификации личности.
Разница для лучшего понимания
Хоть сканирование радужной оболочки и сетчатки глаза являются “глазно-основанными” биометрическими технологиями,есть еще определенные различия, которые помогут различить два метода. Радужная оболочка глаза всегда описывается как идеальная часть человеческого тела для биометрической идентификации. Причины указанны ниже:

Что же касается других преимуществ Распознавание радужки глаза , есть гораздо больше пунктов о которых заслуженно следует упомянуть. С запуском HOMTOM HT10 это принесет более экстраординарный и удивительный опыт для всех.
Технология сканирования радужной оболочки глаза была впервые предложена в 1936 году офтальмологом Франком Буршем. Он заявил, что радужная оболочка глаза каждого человека является уникальной. Вероятность ее совпадения составляет примерно 10 в минус 78-ой степени, что значительно выше, чем при дактилоскопии. Согласно теории вероятности, за всю историю человечества еще не было двух людей, у которых бы совпал узор глаза. В начале 90-х Джон Дафман из компании Iridian Technologies запатентовал алгоритм для обнаружения различий радужной оболочки глаза. На данный момент этот способ биометрической аутентификации является одним из наиболее эффективных и производится с помощью специального сенсора - иридосканера.
Радужная оболочка глаза - это тонкая подвижная диафрагма со зрачком в центре, которая расположена за роговицей перед хрусталиком глаза. Она образовывается ещё до рождения человека и не меняется на протяжении всей жизни. По текстуре радужная оболочка напоминает сеть с большим количеством кругов, при этом ее рисунок очень сложен, что позволяет отобрать порядка 200 точек, с помощью которых обеспечивается высокая степень надежности аутентификации.
Сканер радужной оболочки глаза часто ошибочно называют сканером сетчатки. Отличие заключается в том, что сетчатка расположена внутри глаза и просканировать ее оптическим сенсором невозможно, только с помощью инфракрасного излучения. При этом анализируется не сама сетчатка, а узор кровеносных сосудов глазного дна. Называть подобный сенсор иридосканером неправильно, так как iris – это радужка, сетчатка же имеет название retina.

В основе иридосканера современного смартфона лежит высококонтрастная камера, подобная обычной камере. Иногда роль сканера радужной оболочки может выполнять и обычная фронтальная камера. Процесс аутентификации начинается с получения детального изображения глаза человека. Для этой цели используют монохромную камеру с неяркой подсветкой, которая чувствительна к инфракрасному излучению и позволяет работать в условиях недостаточной освещенности. Обычно делается серия из нескольких фотографий, так как зрачок чувствителен к свету и постоянно меняет свой размер. Затем из полученных фотографий выбирается одна наиболее удачная, определяются границы радужки и контрольная область. К каждой точке выбранной области применяют специальные фильтры, чтобы извлечь фазовую информацию и преобразовать рисунок оболочки в цифровой формат. Очки и контактные линзы, даже цветные, не влияют на качество аутентификации.

Внедрение сканера радужной оболочки глаза в смартфоны началось в 2015 году. Первыми его стали устанавливать китайские и японские производители. В частности первопроходцем был ViewSonic V55, так и не поступивший в массовую продажу. Из самых новых устройств, оснащенных иридосканером, можно выделить Samsung Galaxy S8, однако его сканер с легкостью удалось обмануть хакерам, распечатавшим фотографию на принтере и положившим на нее контактную линзу.
Технология сканирования радужной оболочки глаза была впервые предложена в 1936 году офтальмологом Франком Буршем. Он заявил, что радужная оболочка глаза каждого человека является уникальной. Вероятность ее совпадения составляет примерно 10 в минус 78-ой степени, что значительно выше, чем при дактилоскопии. Согласно теории вероятности, за всю историю человечества еще не было двух людей, у которых бы совпал узор глаза. В начале 90-х Джон Дафман из компании Iridian Technologies запатентовал алгоритм для обнаружения различий радужной оболочки глаза. На данный момент этот способ биометрической аутентификации является одним из наиболее эффективных и производится с помощью специального сенсора - иридосканера.
Радужная оболочка глаза - это тонкая подвижная диафрагма со зрачком в центре, которая расположена за роговицей перед хрусталиком глаза. Она образовывается ещё до рождения человека и не меняется на протяжении всей жизни. По текстуре радужная оболочка напоминает сеть с большим количеством кругов, при этом ее рисунок очень сложен, что позволяет отобрать порядка 200 точек, с помощью которых обеспечивается высокая степень надежности аутентификации.
Сканер радужной оболочки глаза часто ошибочно называют сканером сетчатки. Отличие заключается в том, что сетчатка расположена внутри глаза и просканировать ее оптическим сенсором невозможно, только с помощью инфракрасного излучения. При этом анализируется не сама сетчатка, а узор кровеносных сосудов глазного дна. Называть подобный сенсор иридосканером неправильно, так как iris – это радужка, сетчатка же имеет название retina.
В основе иридосканера современного смартфона лежит высококонтрастная камера, подобная обычной камере. Иногда роль сканера радужной оболочки может выполнять и обычная фронтальная камера. Процесс аутентификации начинается с получения детального изображения глаза человека. Для этой цели используют монохромную камеру с неяркой подсветкой, которая чувствительна к инфракрасному излучению и позволяет работать в условиях недостаточной освещенности. Обычно делается серия из нескольких фотографий, так как зрачок чувствителен к свету и постоянно меняет свой размер. Затем из полученных фотографий выбирается одна наиболее удачная, определяются границы радужки и контрольная область. К каждой точке выбранной области применяют специальные фильтры, чтобы извлечь фазовую информацию и преобразовать рисунок оболочки в цифровой формат. Очки и контактные линзы, даже цветные, не влияют на качество аутентификации.
Внедрение сканера радужной оболочки глаза в смартфоны началось в 2015 году. Первыми его стали устанавливать китайские и японские производители. В частности первопроходцем был ViewSonic V55, так и не поступивший в массовую продажу. Из самых новых устройств, оснащенных иридосканером, можно выделить Samsung Galaxy S8, однако его сканер с легкостью удалось обмануть хакерам, распечатавшим фотографию на принтере и положившим на нее контактную линзу.
Одной из наиболее важных проблем при использовании сетчатки глаза для распознавания личности является движение головы или глаза во время сканирования. Из-за этих движений может возникнуть смещение, вращение и масштабирование относительно образца из базы данных (рис. 1).Рис. 1. Результат движения головы и глаза при сканировании сетчатки.
Влияние изменения масштаба на сравнение сетчаток не так критично, как влияние других параметров, поскольку положение головы и глаза более или менее зафиксировано по оси, соответствующей масштабу. В случае, когда масштабирование всё же есть, оно столь мало, что не оказывает практически никакого влияния на сравнение сетчаток. Таким образом, основным требованием к алгоритму является устойчивость к вращению и смещению сетчатки.
Алгоритмы аутентификации по сетчатке глаза можно разделить на два типа: те, которые для извлечения признаков используют алгоритмы сегментации (алгоритм, основанный на методе фазовой корреляции; алгоритм, основанный на поиске точек разветвления) и те, которые извлекают признаки непосредственно с изображения сетчатки (алгоритм, использующий углы Харриса).
В реализации метод фазовой корреляции работает с бинарными изображениями, однако может применяться и для изображений в 8-битном цветовом пространстве.
Пусть и – изображения, одно из которых сдвинуто на относительно другого, а и – их преобразования Фурье, тогда:

Где – кросс-спектр;
– комплексно сопряженное
Вычисляя обратное преобразование Фурье кросс-спектра, получим импульс-функцию:
Найдя максимум этой функции, найдём искомое смещение.
Теперь найдём угол вращения при наличии смещения , используя полярные координаты:

Данная техника не всегда показывает хорошие результаты на практике из-за наличия небольших шумов и того, что часть сосудов может присутствовать на одном изображении и отсутствовать на другом. Чтобы это устранить применяется несколько итераций данного алгоритма, в том числе меняется порядок подачи изображений в функцию и порядок устранения смещения и вращения. На каждой итерации изображения выравниваются, после чего вычисляется их показатель схожести, затем находится максимальный показатель схожести, который и будет конечным результатом сравнения.
Показатель схожести вычисляется следующим образом:
В начале изображения выравниваются при помощи метода фазовой корреляции, описанного в предыдущем разделе. Затем на изображениях ищутся углы (рис. 2).

Рис. 2. Результат поиска углов Харриса на изображениях сетчатки.
Пусть найдена M+1 точка, тогда для каждой j-й точки её декартовы координаты преобразуются в полярные и определяется вектор признаков где

Модель подобия между неизвестным вектором и вектором признаков размера N в точке j определяется следующим образом:

Где – константа, которая определяется ещё до поиска углов Харриса.
Функция описывает близость и похожесть вектора ко всем признакам точки j.
Пусть вектор – вектор признаков первого изображения, где размера K–1, а вектор – вектор признаков второго изображения, где размера J–1, тогда показатель схожести этих изображений вычисляется следующим образом:

Нормировочный коэффициент для similarity равняется
Коэффициент в оригинальной статье предлагается определять по следующему критерию: если разница между гистограммами изображений меньше заранее заданного значения, то = 0.25, в противном случае = 1.

Рис. 3. Типы признаков (слева – точка бифуркации, справа – точка пересечения).
Для поиска точек, как на рис. 3, сегментированные сосуды сжимаются до толщины одного пикселя. Таким образом, можно классифицировать каждую точку сосудов по количеству соседей S:
Далее анализируются 4 соседних пикселя найденной точки, которые ещё не были рассмотрены. Это приводит к 16 возможным конфигурациям (рис. 4). Если пиксель в середине окна не имеет соседей серого цвета, как показано на рис. 4 (a), то он отбрасывается и ищется другой пиксель кровеносных сосудов. В других случаях это либо конечная точка, либо внутренняя (не включая точки бифуркации и пересечения).

Рис. 4. 16 возможных конфигураций четырёх соседних пикселей (белые точки – фон, серые – сосуды). 3 верхних пикселя и один слева уже были проанализированы, поэтому игнорируются. Серые пиксели с крестиком внутри также игнорируются. Точки со стрелочкой внутри – точки, которые могут стать следующим центральным пикселем. Пиксели с чёрной точкой внутри – это конечные точки.
На каждом шаге сосед серого цвета последнего пикселя помечается как пройденный и выбирается следующим центральным пикселем в окошке 3 x 3. Выбор такого соседа определяется следующим критерием: наилучший сосед тот, у которого наибольшее количество непомеченных серых соседей. Такая эвристика обусловлена идеей поддержания однопиксельной толщины в середине сосуда, где большее число соседей серого цвета.
Из вышеизложенного алгоритма следует, что он приводит к разъединению сосудов. Также сосуды могут разъединиться ещё на этапе сегментации. Поэтому необходимо соединить их обратно.
Для восстановления связи между двумя близлежащими конечными точками определяются углы и как на рис. 5, и если они меньше заранее заданного угла то конечные точки объединяются.

Рис. 5. Объединение конечных точек после сжатия.
Чтобы восстановить точки бифуркации и пересечения (рис. 6) для каждой конечной точки вычисляется её направление, после чего производится расширение сегмента фиксированной длины Если это расширение пересекается с другим сегментом, то найдена точка бифуркации либо пересечения.

Рис. 6. Восстановление точки бифуркации.
Точка пересечения представляет собой две точки бифуркации, поэтому для упрощения задачи можно искать только точки бифуркации. Чтобы удалить ложные выбросы, вызванные точками пересечения, можно отбрасывать точки, которые находится слишком близко к другой найденной точке.
Для нахождения точек пересечения необходим дополнительный анализ (рис. 7).

Рис. 7. Классификация точек разветвления по количеству пересечений сосудов с окружностью. (a) Точка бифуркации. (b) Точка пересечения.
Как видно на рис. 7 (b), в зависимости от длины радиуса окружность с центром в точке разветвления может пересекаться с кровеносными сосудами либо в трех, либо в четырёх точках. Поэтому точка разветвления может быть не правильно классифицирована. Чтобы избавиться от этой проблемы используется система голосования, изображённая на рис. 8.

Рис. 8. Схема классификации точек бифуркации и пересечения.
В этой системе голосования точка разветвления классифицируется для трёх различных радиусов по количеству пересечений окружности с кровеносными сосудами. Радиусы определяются как: где и принимают фиксированные значения. При этом вычисляются два значения и означающие количество голосов за то, чтобы точка была классифицирована как точка пересечения и как точка бифуркации соответственно:

Где и – бинарные значения, указывающие идентифицирована ли точка с использованием радиуса как точка пересечения либо как точка бифуркации соответственно.
В случае если то тип точки не определён. Если же значение отличаются друг от друга, то при точка классифицируется как точка пересечения, в противном случае как точка бифуркации.
Само преобразование определяется как:

Где – координаты точки на первом изображении
– на втором изображении
Для нахождения преобразования подобия используются пары контрольных точек. Например, точки определяют вектор где – координаты начала вектора, – длина вектора и – направление вектора. Таким же образом определяется вектор для точек Пример представлен на рис. 9.

Рис. 9. Пример двух пар контрольных точек.
Параметры преобразования подобия находятся из следующих равенств:

Пусть количество найденных точек на первом изображения равняется M, а на втором N, тогда количество пар контрольных точек на первом изображении равно а на втором Таким образом, получаем ![]() возможных преобразований, среди которых верным выбирается то, при котором количество совпавших точек наибольшее.
возможных преобразований, среди которых верным выбирается то, при котором количество совпавших точек наибольшее.
Поскольку значение параметра S близко к единице, то T можно уменьшить, отбрасывая пары точек, неудовлетворяющие следующему неравенству:
![]()
Где – это минимальный порог для параметра
– это максимальный порог для параметра
– пара контрольных точек из
– пара контрольных точек из
После применения одного из возможных вариантов выравнивания для точек и вычисляется показатель схожести:
![]()
Где – пороговая максимальная дистанция между точками.
В случае если то
В некоторых случаях обе точки могут иметь хорошее значение похожести с точкой . Это случается, когда и находятся близко друг к другу. Для определения наиболее подходящей пары вычисляется вероятность схожести:
Где
Если то
Чтобы найти количество совпавших точек строится матрица Q размера M x N так, что в i-й строке и j-м столбце содержится
Затем в матрице Q ищется максимальный ненулевой элемент. Пусть этот элемент содержится в -й строке и -м столбце, тогда точки и определяются как совпавшие, а -я строка и -й столбец обнуляются. После чего опять ищется максимальный элемент. Поиск таких максимумов повторяется до тех пор, пока все элементы матрицы Q не обнулятся. На выходе алгоритма получаем количество совпавших точек C.
Метрику схожести двух сетчаток можно определить несколькими способами:
Где – параметр, который вводится для настройки влияния количества совпавших точек;
f выбирается одним из следующих вариантов:

Метрика нормализуется одним из двух способов:

Где и – некоторые константы.

Рис. 10. Углы, образованные точками разветвления, в качестве дополнительных признаков.
Также можно применять шифр гаммирования. Как известно, сложение по модулю 2 является абсолютно стойким шифром, когда длина ключа равна длине текста, а поскольку количество точек бифуркации и пересечения не превышает порядка 100, но всё же больше длины обычных паролей, то в качестве ключа можно использовать комбинацию хешей пароля. Это избавляет от необходимости хранить в базе данных сетчатки глаза и хеши паролей. Нужно хранить только координаты, зашифрованные абсолютно стойким шифром.
Также была предпринята попытка реализации алгоритма, использующего углы Харриса, но получить удовлетворительных результатов не удалось. Как и в предыдущем алгоритме, возникла проблема в устранении вращения и смещения при помощи метода фазовой корреляции. Вторая проблема связана с недостатками алгоритма поиска углов Харриса. При одном и том же пороговом значении для отсева точек, количество найденных точек может оказаться либо слишком большим либо слишком малым.
В дальнейших планах стоит разработка алгоритма, основанного на поиске точек разветвления. Он требует гораздо меньше вычислительных ресурсов по сравнению с алгоритмом, основанном на методе фазовой корреляции. Кроме того, существуют возможности для его усложнения в целях сведения к минимуму вероятности взлома системы.
Другим интересным направлением в дальнейших исследованиях является разработка автоматических систем для ранней диагностики заболеваний, таких как глаукома, сахарный диабет, атеросклероз и многие другие.
P.s. по немногочисленным просьбам выкладываю
Первые сообщения о «взломе» биометрических систем защиты флагманских смартфонов компании Samsung (Galaxy S8 и S8+) фактически в день их презентации, в конце марта 2017 года. Напомню, что тогда испанский испанский обозреватель MarcianoTech вел прямую Periscope-трансляцию с мероприятия Samsung и обманул систему распознавания лиц в прямом эфире. Он сделал селфи на собственный телефон и продемонстрировал полученное фото Galaxy S8. Как это ни странно, этот простейший трюк сработал, и смартфон был разблокирован.
Однако флагманы Samsung комплектуются сразу несколькими биометрическими системами: сканером отпечатков пальцев, системой распознавания радужной оболочки глаза и системой распознавания лиц. Казалось бы, сканеры отпечатков и радужной оболочки должны быть надежнее? По всей видимости, нет.
Исследователи Chaos Computer Club (CCC) сообщают , что им удалось обмануть сканер радужной оболочки глаза с помощью обыкновенной фотографии, сделанной со средней дистанции. Так, известный специалист Ян «Starbug» Криссер (Jan Krissler) пишет, что достаточно сфотографировать владельца Galaxy S8 таким образом, чтобы его глаза были видны в кадре. Затем нужно распечатать полученное фото и продемонстрировать его фронтальной камере устройства.
Единственная сложность заключается в том, что современные сканеры радужной оболочки глаза (равно как и системы распознавания лиц) умеют отличать 2D-изображения от реального человеческого глаза или лица в 3D. Но Starbug с легкостью преодолел и эту сложность: он попросту приклеил контактную линзу поверх фотографии глаза, и этого оказалось достаточно.
Для достижения наилучшего результата специалист советует делать фото в режиме ночной съемки, так как это позволит уловить больше деталей, особенно если глаза жертвы темного цвета. Также Крисслер пишет, что распечатывать фотографии лучше на лазерных принтерах компании Samsung (какая ирония).
«Хорошей цифровой камеры с линзой 200 мм будет вполне достаточно, чтобы с расстояния до пяти метров захватить изображение, пригодное для обмана системы распознавания радужной оболочки глаза», - резюмирует Крисслер.
Данная атака может оказаться куда опаснее, чем банальный обман системы распознавания лиц, ведь если последнюю нельзя использовать для подтверждения платежей в Samsung Pay, то радужную оболочку глаза для этого использовать как раз можно. Найти качественную фотографию жертвы в наши дни явно не составит труда, и в итоге атакующий сможет не просто разблокировать устройство и получить доступ к информации пользователя, но и похитить средства из чужого кошелька Samsung Pay.
Специалисты Chaos Computer Club предупреждают пользователей, что не стоит доверять биометрическим системам защиты сверх меры и рекомендуют применять старые добрые PIN-коды и графические пароли.
Видеоролик ниже пошагово иллюстрирует все этапы создания фальшивого «глаза» и демонстрирует последующий обман Samsung Galaxy S8.
Представители компании Samsung прокомментировали ситуацию:
"Компании известно об этом сообщении. Samsung заверяет пользователей, что технология распознавания радужной оболочки глаза в Galaxy S8 была разработана и внедрена после тщательного тестирования, чтобы обеспечить высокий уровень точности сканирования и предотвратить попытки несанкционированного доступа.
Описываемый в упомянутом материале способ может быть реализован только с использованием сложной техники и совпадении ряда обстоятельств. Нужна фотография сетчатки высокого разрешения, сделанная на ИК-камеру, контактные линзы и сам смартфон. В ходе внутреннего расследования было установлено, что добиться результата при использовании такого метода невероятно сложно.
Тем не менее, даже при наличии потенциальной уязвимости, специалисты компании приложат все усилия, чтобы в кратчайшие сроки обеспечить безопасность конфиденциальных и личных данных пользователей".
| Статьи по теме: | |
|
Школьная энциклопедия К какой расе относятся сирийцы
90 % населения Сирии составляют мусульмане, 10% христиане. Мусульмане... Лимонный кекс на кефире с маком
Лимонный кекс на кефире без яиц (с пропиткой) — мой любимый рецепт к... Салат из сайры - простые и оригинальные рецепты аппетитной закуски Салат из сайры консервированной с рисом
Я очень люблю салаты с консервированной рыбой. Их можно готовить... | |